AI勉強用、データの前処理
背景と目的
AIを勉強していると学習用のデータを準備するのが面倒とか難しいと思うことがあります。 画像データの準備方法とそれ用のスクリプトを作成したのでまとめておきます。
内容
本記事で行う内容は以下の通りです。
AIの勉強用途で用いる複数の有名人の画像データをgoogle-images-downloadで取得する。取得した画像データを人物毎に異なるディレクトリに保存します。
取得した画像データに対してAIで学習用データとして使用できるよう下記の処理を自作のpythonスクリプトで実行します。
- 顔部分を抽出
- 画像のピクセル数を統一する
- 白黒画像に変換する
自作のコードの大きな特徴として以下の2点があります。
- 一度のコマンドで複数のディレクトリに対して処理を実行する
- 画像データに複数の人物の顔が含まれている場合はAI用データとして使用しない(データの確認・削除の手間を省くため)
環境
本内容は、Windows11のWSLで実行しました。
特定の画像データを取得する方法
画像認識を行うにあたって、特定の人物、主に著名な有名人の顔画像のデータを多数あればいいのになぁと思うことがあります。そんなときはgoogle-images-downloadを使用すれば簡単にデータを取得できます。
google-images-download
google-images-downloadとは特定の検索ワードに引っかかる画像データを指定した枚数分だけ取得してくれる便利機能です。使うための前準備としては、2ステップで完了します。 まずは作業ディレクトリで以下コマンドを実行します。
git clone https://github.com/Joeclinton1/google-images-download.git gid-joeclinton pip install -e gid-joeclinton
次に下記コマンドで取得したい画像を任意のキーワードから取得します。 'リンゴ'の画像を10枚取得する場合は、以下のコマンドを実行します。
googleimagesdownload -l 10 -k "リンゴ"
これで、作業ディレクトリの直下にdownloadsディレクトリが生成され、その中にリンゴの画像が10枚保存されたリンゴという名前のディレクトリが生成されます。
ちなみに-l 10は取得するデータ数を指定するもので、デフォルトでは100となります。上限も100となっています。
検索ワードとして複数のワードをカンマ区切りとすると、一度のコマンドで複数のワードのディレクトリが生成されそれぞれのディレクトリに各画像が保存されます。
AI用にデータを取得する
AI用のデータとしては異なる複数の人物の画像を取得します。下記のコマンドを作業ディレクトリで実行して今をときめく若手女優の画像データを取得しましょう。
googleimagesdownload -k "橋本環奈,広瀬すず,浜辺美波,福原遥"
たったこれだけで今をときめく若手女優4名の画像がそれぞれ100枚取得できます。

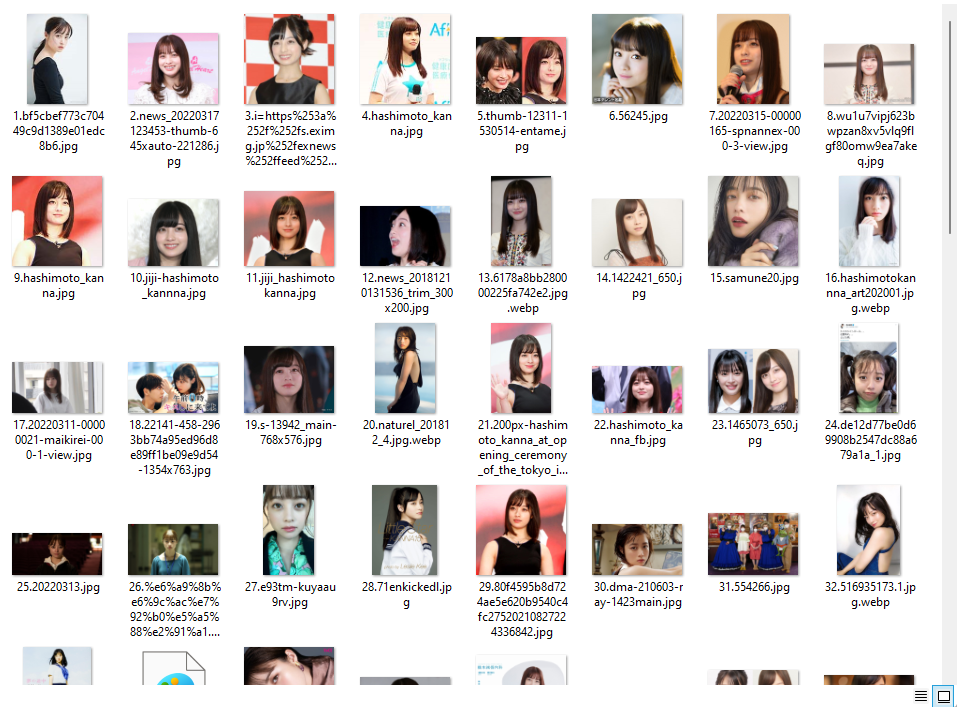
A用にデータを調整する
橋本環奈ディレクトリ内の画像は趣味として閲覧する分にはそれで十分ですが、AI用のデータとしては以下の点で不十分です。
- 顔以外の情報が含まれる
- 画像によって画素数が異なる
- カラー画像ではAI計算時の負荷が大きい
上記の対応(取得した画像データから顔部分だけをトリミング、画像の縦横のピクセル数を統一、白黒画像に変換)を行うスクリプトをpythonで作成しました。 本コードの特徴として以下の2点があります(再掲)。
1.一度のコマンドで複数のディレクトリに対して処理を実行する 1. 画像データに複数の人物の顔が含まれている場合はAI用データとして使用しない(データの確認・削除の手間を省くため)
本スクリプトは 作業ディレクトリ直下のdownloadsディレクトリに保存する前提で作成しています。ここではファイル名をtrim_images.pyとして話を進めます。
#!/usr/bin/python import cv2 import os from PIL import Image output_size = 64 #Output image width and height HAAR_FILE = './haarcascade_frontalface_alt2.xml' cascade = cv2.CascadeClassifier(HAAR_FILE) path = './' contents = os.listdir(path) direcs = [f for f in contents if os.path.isdir(os.path.join(path, f))] for direc in direcs: path = './' + direc contents = os.listdir(path) files = [f for f in contents if os.path.isfile(os.path.join(path, f))] output_dir = './' + 'output_'+ direc if not os.path.exists(output_dir): os.mkdir(output_dir) index = 1 for img_file in files: path = './' + direc + '/' + img_file img = cv2.imread(path, cv2.IMREAD_COLOR) try: img_g = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #Convert to a gray scale image except: print('ERROR: ' + path) continue faces = cascade.detectMultiScale(img_g, minSize=(30,30)) if len(faces) == 1: (x,y,w,h) = faces[0] if max(w, h) == w: trim = img_g[y+int((h-w)/2):y+int((h+w)/2), x:x+w] else: trim = img_g[y:y+h, x+int((w-h)/2):x+int((w+h)/2)] save_file = output_dir + '/' + 'no_' + str(index) + '.jpg' cv2.imwrite(save_file, trim) base_img = Image.open(save_file) resize_g = base_img.resize((output_size, output_size)) resize_g.save(save_file) index += 1 print(direc + ': ' + str(index) + ' pics.')
作業ディレクトリに上記コードを作成し実行します。
実行するにあたってはdownloadsディレクトリにhaarcascade_frontalface_alt2.xmlを保存しておく必要があります。haarcascade_frontalface_alt2.xmlは以下のgithubからダウンロードするか内容をコピーして作成してください。
また、上記スクリプトを実行する際はopencvとpillowのインストールが必要です。それぞれ下記コマンドでインストールできます。
sudo pip3 install python-opencv sudo pip3 install pillow
エラーが出た場合は下記コマンドでpipをupgradeし再度インストールを試みてください。
python3 -m pip install --upgrade pip
準備が済んだのちにtrim_images.pyを下記コマンドにて実行します。
python3 trim_images.py
するとdownloadディレクトリ内に新たに4つのディレクトリが生成されます。
output_橋本環奈 output_広瀬すず otuput_福原遥 output_浜辺美波

各ディレクトリを確認すると、いずれの画像も白黒でサイズが等しくなっていることがわかります。

ただ残念なことに、google-images-downloadで取得したデータ自体に問題があり、異なる人物の顔画像や顔以外のものが顔として認識されて画像として保存されていることがわかります。手間ですが不要なデータはマニュアル操作で削除する必要があります。
まとめ
以下の2コマンドでありとあらゆる著名人のAI学習用画像が取得できるようになりました。
googleimagesdownload -k "" python3 trim_images.py
これでAIの勉強が加速するはずです、多分。
以上です。